Обо мне
🧔 Кто я¶
👋 Привет!
Я Вячеслав Колупаев, MLOps Engineer.
Специализируюсь на задачах на пересечении ML Engineering, DevOps/MLOps и SRE. Я фокусируюсь на инженерии, а не на самом ML. Я не обучаю модели. Делаю так, чтобы ML-проекты доезжали до продуктивной среды и стабильно в ней работали. Довожу дела до конца.
За счет T-shaped набора компетенций способен решать сложные и комплексные инженерные задачи на стыке разных дисциплин.
Владею нужными технологиями и навыками, четко излагаю мысли, делаю сначала то, что важно для достижения целей. Проявляю инициативу и лидирую других.
Умею спроектировать систему и заставить её работать из того, что есть с минимальными затратами на дополнительные ресурсы. Ко мне обращаются, когда хотят результативности: и на деле, а не в презентациях и страничках Confluence.
Постоянно учусь. Осмысленно и по плану.
Когда я не смогу помочь
Я не смогу помочь, если:
- Вам нужен узкий специалист, кодер или решатель алгоритмических задач.
- Ваша позиция предполагает people management.
- Вы ищете эксперта дешевле рынка.
- Вы ищете сотрудника для работы в офисе.
Это моя записная книжка и блог с заметками о технологиях и событиях в моей жизни. Я их создал для себя. У меня нет каналов в Telegram или Youtube.
👨💻 Некоторые факты обо мне¶
Note
Постоянно проживаю в 🇷🇺 РФ и не планирую никуда уезжать. Военный билет есть.
Технологии¶
- Я люблю ❤️ программирование ещё со школы. Мой первый компьютер был
ZX Spectrum(Magic 05). Свои первые программы я написал наBasicи сохранил на магнитофонную ленту. - 👨🎓 Высшее образование по профилю работы: Институт математики, естественных наук и информационных технологий, специальность «Прикладная информатика в экономике».
- Карьеру начинал оператором технической поддержки Интернет. Прошел все ступени инженерного роста: оператор техподдержки → инженер → руководитель группы инженеров → руководитель проектов → руководитель программ (несколько взаимосвязанных проектов в программе) → менеджер по продажам проектов → руководитель отдела продаж проектных решений → основатель SaaS стартапа → партнер в компании по разработке на Битрикс → бэкенд-разработчик → старший бэкенд-разработчик → Senior Software Engineer в Machine Learning команде.
- 👨🔧 Есть опыт планирования, самостоятельной разработки с нуля, лидирования групповой разработки и вывода в продуктивную среду микросервисов.
Надёжность¶
- Доверяли ответственные направления, потому что надёжен, умею общаться с людьми и решать проблемы.
- Имею опыт проектирование и реализации сложных проектных решений. Свой первый проект я реализовал в 24 года. Лично изучил потребности бизнеса, спланировал, собрал команду и реализовал с нуля проект по модернизации ИТ-инфраструктуры в предприятии оптовой торговли. Проект состоял из 2-х очередей и включал 9 локаций: центральный офис + 8 филиалов. Бюджет проекта ~5 млн. руб. в ценах 2006 года.
- Реализовывал проекты лично. Руководил проектами (бюджет до 50 млн. руб. в ценах 2012 года; до 26 локаций), программами проектов (до 14 проектов в программе). Координировал усилия команд до 55 человек из 7 организаций для достижения целей проекта.
- Есть предпринимательский опыт. Придумал идею, собрал продуктовую команду, получил инвестиции и запустил с
нуля web&mobile SaaS start-up — агрегатор наличия лекарств и цен на них в аптеках
"Таблеткин / Tabletkin". - Люди доверяют мне. Пять лет был председателем ревизионной комиссии в гаражном кооперативе на 600 человек. Четырнадцать лет являюсь старшим по подъезду в многоквартирном доме.
⭐️ Что я хочу¶
Моя текущая цель: занять позицию Technical Lead / Technical Architect в ML Platform или AI/ML Complicated Subsystem Team.
Получение экспертизы занимает много времени
Есть большая разница между тем, о чем ты знаешь немного и тем, в чем ты действительно хорош. Трудно быть экспертом сразу во многих технологиях. Получение экспертизы занимает много времени.
Например, если на вопрос, какую СУБД выбрать для проекта и почему, Team Lead ответит: "PostgreSQL, просто потому
что я работал с ним на прошлом проекте", то это будет нормально.
От архитектора же ожидается аргументированный ответ, основанный на требованиях стейкхолдеров, ограничениях, сравнительном анализе технических характеристик, опыте реализаций проектов и т.п.
Моя долгосрочная цель, которая, возможно, будет скорректирована позднее: ещё после нескольких завершенных проектов, получения опыта их эксплуатации и множество набитых шишек — стать Архитектором решений / Solutions Architect в AI/ML подразделении.
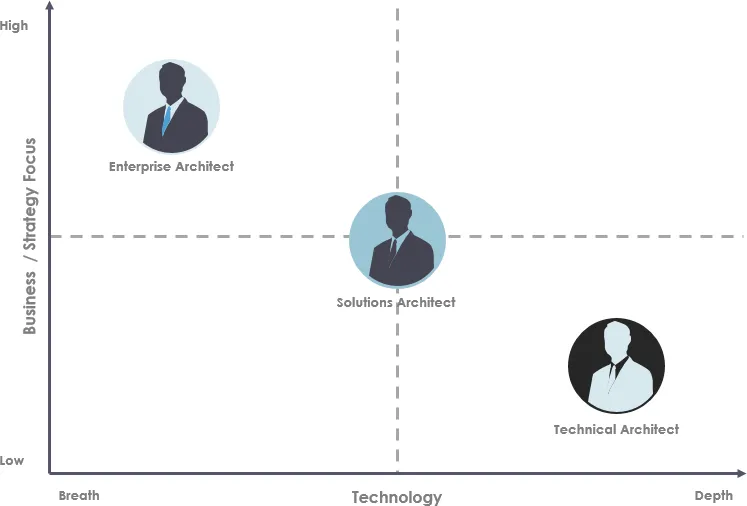
О роли архитектора решений >>
Роль архитектора решений предполагает следующие активности:
- Проектирование гибких, масштабируемых, высоконагруженных систем в области больших данных;
- Анализ функциональных и нефункциональных требований в контексте архитектуры системы;
- Оценку требований бизнес заказчика на предмет возможных способов реализации;
- Внедрение новых технологий и решение технических проблем;
- R&D ключевых участков подсистем;
- Контроль исполнения принятых архитектурных принципов и решений;
- Описание технических решений, используемых в создаваемом продукте;
- Участие в постановке задач аналитикам и разработчикам ML.
Для этого потребуется:
- Опыт разработки высоконагруженных приложений на базе микросервисной архитектуры в качестве системного архитектора;
- Хорошее знание шаблонов проектирования;
- Опыт разработки архитектурной документации (компонентная, функциональная, развертывания и т.д.);
- Опыт разработки и согласования SLA;
- Знания платформы
Kubernetes/OpenShift; - Опыт работы с ORM frameworks;
- Опыт работы с системами кэширования (
Redis/Tarantool/Gridgainи т.п.); - Опыт работы с Message-oriented middleware (
Kafka,Rabbit MQ,Websphere MQи т.д.); - Уверенное знание методологий принципов разработки ПО, включая гибкие (
Agile,SCRUM).
Я не хочу в чистый people management
Мне интересен путь технического эксперта. Мне действительно нравится ❤️ работа с инженерией.
У современных руководителей на это просто нет времени — у них календари "в три этажа" и они не вылазят с встреч.
🎯 Опыт работы и достижения¶
Опыт в числах
- 5,5+ лет опыта коммерческой разработки на Python; 4 проекта в продуктивной среде — созданы с нуля; получен опыт эксплуатации созданных систем.
- 3+ года в банковской отрасли.
- 6,5 лет опыта работы с programmatic интернет-рекламой и веб-аналитикой со стороны агентства и площадки.
- 1,5 года драйва в своем web&mobile SaaS start-up.
- 6,5 лет опыта управления проектами IT-инфраструктуры, программами и портфелем проектов в интеграторе.
- 2,5 года опыта работы руководителем группы IT-инженеров в команде эксплуатации. Дизайн и администрирование Microsoft Active Directory и сети Cisco на 500+ хостов.
- 3 года опыта работы инженером (во время учёбы в университете), включая техподдержку.
Ниже я привел описание только текущего и четырёх последних мест работы, т.к. они наиболее релевантны. Это охватывает период с декабря 2018 года по сегодняшний день.
1. Иннотех¶
Январь 2025 — настоящее время.
Архитектор решений (Solution Architect). Стрим: «Сервисы для работы с большими данными». Домен: «Искусственный интеллект».
Success
Это путешествие еще только началось. А пока, я рад достижению своей цели🚀.
2. RUTUBE¶
Сентябрь 2024 — Январь 2025 (4,5 месяца).
Senior MLOps Engineer в отделе развития и эксплуатации систем машинного обучения и отчетности департамента технического развития. Точное название должности: «Ведущий инженер-программист».
-
Сократил потребление RAM инстансов real-time ML-микросервиса рекомендаций на 50% без изменения исходного кода. Достигнуто за счёт оптимизации настроек сервера приложений uWSGI под специфическую рабочую нагрузку. Это позволило запустить uWSGI с большим числом workers на том же числе CPU и за счёт этого уменьшить latency на 25%. Так же это сократило время запуска подов в 2 раза за счет исключения необходимости повторно скачивать артефакты ML-модели из хранилища.
-
Обнаружил утечку памяти ML-приложения рекомендаций. Реализовал решение по превентивному респауну uWSGI workers для снижения влияния утечки. Респаун происходит до 1 секунды. Это позволило избежать перерывов в работе подов из-за падения по OOM и последующего долгого рестарта в Kubernetes. Исчезла необходимость в выкачивании ML-артефактов из хранилища во время рестарта подов по OOM, т.к. респауны uWSGI workers выполняются путем форка мастер-процесса, когда артефакты уже хранятся в RAM. Так же это позволило снизить требуемую квоту RAM для запуска и работы микросервиса в 2 раза.
Tip
Приведенное выше является знанием, которое влияет system-wide. т.к. все ML-микросервисы на Python работают на сервере приложений uWSGI, потребляемая RAM измеряется ТБ, а число vCPU идет на тысячи.
Эти меры не только улучшают производительность системы, но и существенно снижают затраты компании на инфраструктуру, обеспечивая более эффективное распределение ресурсов и экономию бюджета.
И самое главное — это устраняет барьеры для повышения качества рекомендаций, так как чрезмерное потребление ресурсов, особенно оперативной памяти, ранее ограничивало использование ML-моделей, обученных на более продолжительных временных интервалах.
-
Доработал рекомендательный сервис на базе Alternating Least Squares, чтобы он смог давать рекомендации к большему числу item из запроса на тех же вычислительных ресурсах и в рамках SLO. Проработал постановку задачи и логику решения, разработал прототип, создал среду для нагрузочного тестирования, выполнил нагрузочное тестирование, доработал приложение, проуправлял задачей по канареечному деплою в продуктивную среду (A/B-тест на небольшом % трафика), задокументировал.
3. ПАО РОСБАНК¶
Март 2022 — Август 2024 (2 года 6 месяцев).
Senior Software Engineer — Machine Learning в Enabling & Complicated Subsystem Team 🔥 департамента централизованного управления данными. Точное название должности: «Менеджер по разработке моделей машинного обучения».
🥇 Главное достижение
🏁 Спроектировал, лидировал разработку и вывел в продуктивную среду 2 ML-проекта на Python: один с batch, другой с online процессингом.
Решил сложные инженерные задачи, которые ранее никто не смог или не захотел сделать. Прошел через все бюрократические и организационные препятствия, и довел дело до конца.
Протоптал первые тропинки для будущих ML-проектов. Обеспечил появление ранее отсутствующего Development Environment для ML-разработчика.
О команде >>
Enabling team — команда, которая призвана изучать передовые технологии, концепции и подходы и способствовать их проникновению в stream-aligned teams. Особенность данного случая в том, что enabling team была использована как некий спецназ в мире ML-разработки, чтобы решить проблему «курицы и яйца».
Дело в том, что когда я пришел в команду, то обнаружил, что для разработки на Python и, тем более, командной
разработки и деплоя проектов, нет ровным счетом ни-че-го.
Результат, как говорится, на табло: за все время, даже в тестовую среду не был выведен ни один контейнеризированный ML-проект. Из-за этого ML-платформа не могла подпитываться из stream-aligned teams и облегчать запуск новых проектов.
Руководству нужно было, чтобы кто-то вывел всех из замкнутого круга. Поэтому мне поручили продуктивизацию ML-проектов для stream-aligned teams.
Получилось как в старом анекдоте:
Обувная фирма направила двух представителей в разные регионы Африки. Через неделю приходят два сообщения.
Один представитель пишет: «😟 Все пропало, бизнеса не будет, здесь все ходят босиком».
Другой при тех же обстоятельствах сообщает: «😀 Прекрасные перспективы, конкурентов нет, так что мы будем первыми, кто обует эту страну».
Описание моих достижений приведено в следующих вкладках:
ℹ️ О проекте >>
Проект представляет из себя N отдельных микросервисов на Python для выполнения online предсказаний с помощью предобученных ML-моделей. Сначала были созданы 2 микросервиса, затем постепенно добавляли другие.
Изначально, по требованиям заказчика, коммуникация с upstream планировалась с помощью RESTful API. Затем удалось
изменить на асинхронную, с помощью брокера сообщений IBM MQ.
Типичная нагрузка небольшая, но могут быть спайки, превышающие обычную нагрузку в сотни раз, поэтому пришлось тщательно планировать ресурсы, способы rate limiting, retry и idempotency.
Деплой выполняется в OpenShift в трёх средах, на основном и DR-кластере. Отсюда особенность проекта: N
namespaces * 3 среды * 2 кластера = 6N namespaces. При ограниченном ресурсе инженеров качественно управлять такой
инфраструктурой очень трудно. Поэтому я решил применить подход GitOps на базе ArgoCD + kustomize + git.
Особенностью проекта является то, что это был первый ML-проект подобного рода в компании.
🧑💻 Команда >>
В данном проекте я отвечал за: системную архитектуру, частично солюшн архитектуру, разработку и координацию командной работы, инженерию и то, чтобы проект доехал до продуктивной среды. Я не исполнял роль Data Scientist и не обучал модель.
Изначально проект стартовал в составе: 1 PM (part-time), 1 MLE (это я, причем я работал еще на втором проекте одновременно), 2 DevOps-инженера (part-time).
Позднее добавился DevOps Lead (появилась экспертиза и управление) и Solution Architect (part-time). В этот момент я перестал заниматься общением с заказчиком и вопросами солюшн архитектуры и смог сконцентрироваться на разработке.
По ходу дела к проекту добавили ресурс разработчиков в виде 1 DS и 1 DE.
🚀 Итог >>
Проект сейчас работает в продуктивной среде и приносит выгоду компании. Результат признан положительным, выполняется масштабирование.

Я сам стал более лучшим инженером, чем был ранее, т.к. в этом проекте я частично исполнял роль архитектора. Для этого мне пришлось много читать о системном дизайне. В результате, я разработал первую версию своего Solution Architect фреймворка и наметил план по его дальнейшему развитию.
Вот, что конкретно я сделал в этом проекте:
Планирование >>
- Провел интервью нескольких стейкхолдеров и технических специалистов заказчика, выявил некоторые требования и ограничения. Выполнил расчет и согласование SLA в части ожидаемых latency и RPS.
- Разработал PoC — stateless контейнеризированное ML-приложения на базе
FastAPIдля online prediction задачи. Первым в департаменте запустил в тестовой средеOpenShift. Разработал инструмент для нагрузочного тестирования ML-приложений на базе библиотекиlocust. Выполнил нагрузочное тестирование. Подготовил и провел презентацию о результатах для стейкхолдеров. Это позволило стейкхолдерам принять решение о старте проекта. - Спроектировал Системную архитектуру для деплоя микросервисов в
OpenShift: DEV-среда, репозитории для ОС,Docker-образов,Python-библиотек, кода приложений, сабмодулей, видение и требования кCI/CD+GitOpsна базеArgoCD+kustomize,OpenShiftNamespacesв разных средах на основном иDRкластере. - Декомпозировал проект по реализации Системной архитектуры на отдельные задачи в
Jiraдля DevOps-инженеров. Проуправлял данными задачами.
Разработка >>
- Разработал структуру, конфигурационные файлы проекта, ключевые модули приложения.
- Разработал кастомный логгер для вывода информативных структурированных логов с метаинформацией.
Разработал клиента
Sentry, настроил проект и алерты. - Настроил статические анализаторы кода:
flake8(WPS),mypy,isort. - Сконфигурировал
pytest, разработал некоторые фикстуры и юнит-тесты. - Разработал и подробно задокументировал multi-stage
Dockerfile. Протестировал CI/CD c DevOps-инженерами и задеплоил в тестовую среду. - Разработал клиента для работы работы с
IBM MQс аутентификацией поSSL-сертификатам. Работа осложнялась отсутствием нормальной документации на библиотекуpymqi, поэтому разрабатывал, изучая внутренности библиотеки. Решения подготовлено для работы локально и в контейнере в разных средах. До меня в компании никто не решал эту задачу на Python. Как итог, последующие проекты будут проходить этапы интеграции сIBM MQбыстрее. - Менторил коллег в части разработки на Python: отвечал на вопросы, разбирал ошибки, подсказывал пути решения.
- Выполнял Code Review Pull Requests от коллег.
- Проуправлял деплоем приложения в сертификационную и продуктивные среды: координация с DevOps-инженерами, заказчиком, смежными подсистемами; диагностика и фиксинг багов.
Эксплуатация >>
- Руководил восстановлением системы в продуктивной среде в результате инцидента.
Time to Restore Service(время восстановления) составило 15 минут, включая время на поиск причины. Так быстро благодаря тому, что: в проекте предусмотрены средства диагностики, нагрузка работает вOpenShift(Kubernetes), неймспейсы управляютсяArgoCD. Проуправлял post-mortem анализом (ретроспективой) в команде, включая разработчиков и DevOps-инженеров. Выяснили корневую причину инцидента. Разработали план изменений, как сделать так, чтобы такое не было возможно в принципе — чтобы исключить человеческий фактор. Проуправлял задачами по реализации плана.
ℹ️ О проекте >>
Проект представляет из себя ML-приложение на Python, работающее в Docker-контейнере и запускающееся по расписанию. Приложение ресурсоемкое по CPU — при запуске производится обучение ML-модели, прогнозирование, оптимизация прогноза. Из-за этого пришлось размещать приложение на выделенной виртуальной машине с достаточными ресурсами по CPU.
🧑💻 Команда >>
В данном проекте я отвечал за: разработку, инженерию и то, чтобы проект доехал до продуктивной среды. Я не исполнял роль Data Scientist и не обучал модель.
На входе я получил Jupyter Notebook от DS.
🚀 Итог >>
Стоимость процесса для 1640 АТМ снизилась на 17%.

Вот, что я сделал в этом проекте:
Планирование >>
- Провел интервью нескольких стейкхолдеров и технических специалистов заказчика, выявил некоторые требования и ограничения.
- Протащил в контур банка через ДИБ необходимые для разработки библиотеки и системные пакеты.
- Спроектировал Системную архитектуру для деплоя приложения. Придумал решение для запуска приложеиния по
расписанию при завершении работы ETL-пайплайна в
Apache Airflow. - Декомпозировал проект по реализации Системной архитектуры на отдельные задачи в
Jiraдля DevOps-инженеров . Проуправлял данными задачами.
Разработка >>
- Разработал структуру, конфигурационные файлы проекта, ключевые модули приложения.
- Разработал кастомный логгер для вывода информативных структурированных логов с метаинформацией.
Разработал клиента
Sentry, настроил проект и алерты. - Настроил статические анализаторы кода:
flake8(WPS),mypy,isort. - Сконфигурировал
pytest, разработал некоторые фикстуры и юнит-тесты. - Разработал и подробно задокументировал multi-stage
Dockerfile. Протестировал CI/CD c DevOps-инженерами и задеплоил в тестовую среду. - Разработал клиента для работы с
Hiveс аутентификацией поKerberos. Решения подготовлены для работы локально и в контейнере в разных средах. До меня в компании никто не решал эту задачу на Python. Другие команды просто отказывались от интеграций сHive. Как итог, последующие проекты будут проходить этапы интеграции сHiveбыстрее. - Согласовал с ДИБ решение по интеграции со смежной системой на базе СУБД
MS SQL Server. Проуправлял задачей по интеграции, в ходе которой координировал три команды. Офицер ДИБ дал такую обратную связь: "Вы не первые, кто реализовал подобную интеграцию (прим. Речь идет о других системах и языках программирования), но вы первые, кто это сделал так быстро." - Разработал клиента для работы с СУБД
MS SQL Server. Применено шифрование канала с помощьюTLSи аутентификация поKerberos. - Разработал решение по работе приложения с кэшем более чем одной service account и свитчингу кэшей
Kerberos. - Задокументировал сделанную работу, передал заказчику.
Эксплуатация >>
- Решил инцидент с падением приложения в продуктивной среде в результате некорректного действия пользователя смежной системы. Выполнил первичную диагностику, скоординировал других участников проекта для более детальной диагностики. Выполнил анализ кода и данных, и нашел причину. Оперативно связался со службой эксплуатации смежной системы для восстановления. После этого убедился, что все работает нормально. Выполнил post-mortem анализ (ретроспективу) и дал рекомендации заказчику, как сделать так, чтобы такое не было возможно в принципе — чтобы исключить человеческий фактор.
Мотивация. Как оказалось, отсутствие Development Environment являлось одним из ключевых блокеров развития ML-разработки во всем банке. Ранее не нашлось человека, знающего, что нужно сделать, причём в смежных дисциплинах, и при этом способного побороть сопротивление бюрократической машины.
Достижения:
- Обеспечил появление командных репозиториев для
Docker-образов иPython-библиотек, групп безопасностиActive Directory, технических учетных записей. - Организовал появление в контуре банка ранее отсутствовавших зеркал репозиториев
UbuntuиDebian. Это позволило устанавливать системные пакеты вDebian-basedDockerобразыPython. - Чтобы иметь возможность решать производственные задачи, первым в банке развернул Development Environment
ML-разработчика внутри
WSL. Прошел длинный бюрократический путь согласований и донастройки средств ИБ. Это стало триггером положительных изменений в масштабах нескольких департаментов банка. - Разработал подробную инструкцию и комплект
bash-скриптов для автоматизированного развертыванияWSLна ПК ML-разработчика. - Согласовал с ДИБ применение для команды решения для удаленной разработки извне контура банка без доступа к источникам данных. Ранее нам было запрещено.
- Обновил приложения в командном
Microsoft Software Center, чтобы они автоматически стали доступны всем членам команды:Python3.9, 3.10, 3.11,PyСharm,Dockerи т.д. ОбновилPythonвJupyterHub. Организационно сложная задача из-за бюрократии. Теперь версии свежие и они консистентны. Это решило проблему, когда обученные DS модели на библиотеках трёхлетней давности трудно или вовсе не получается собрать вDocker-образ. - Настроил командные
JiraиBitbucketдля более эффективной групповой работы. Настроил удобные представления, формы, вид карточек, flow, отчеты для руководителя проектов. Научил руководителя проектов работать с доской и отчетами. - Нашел в банке команду
Sentryи первым в департаменте осуществил с ними интеграцию. Это позволило регистрировать исключения приложений для оперативного реагирования на них. - Обучил DevOps-инженера основным концепциям работы с
Docker. Ранее подразделение не работало контейнеризированными приложениями. - Внедрил использование
poetryc его продвинутым CLI. Это убрало необходимость поддерживатьbash-скрипты для управления группами зависимостей. Чтобы можно было делать push/pull самописных библиотек, проуправлял задачей по обновлению корпоративного хранилища артефактов. Без этого push не работал. - Внедрил использование
Conventional Commitsи автоматических семантических релизов. Теперь ведение changelog и присвоение тегов образам осуществляется автоматически. - Разработал Python-библиотеку
toolboxдля стабилизированного кода, который редко изменяется. - Создал
Git Submoduleи подключил его в ML-проекты для активно разрабатываемого кода. Он потребовался из-за дефицита ресурсов разработчиков. Drawback в виде coupling мне известен. - Создал репозиторий с эталонным содержанием конфигурационных файлов проектов на базе библиотеки
nitpick. Это позволило о беспечить консистентность настроек ML-проектов. - Разработал библиотеку вспомогательных скриптов на
bash. Используется для автоматизации работы сDocker, получения и рефреша тикетовKerberosи т.п. - Создал инструмент для локальной разработки и тестирования DAG в
Apache Airflow.
4. UnaBank, финтех, Филиппины¶
Май 2021 — Февраль 2022 (10 месяцев).
Senior Software Engineer (Python, back end). Точное название должности: «Риск-технолог».
🥇 Главное достижение
Разработал на Python 3 (FastAPI, asyncio, aiohttp, SQLAlchemy, PostgreSQL,
Databases, alembic) с нуля и запустил в продуктивную среду (AWS) микросервис риск-модуля.
Решение создано полностью на OpenSource ПО и не содержит Vendor Lock.
С момента запуска он оценил несколько миллионов заявок на кредит в соответствии с SLA.
Для этого я:
- Пообщался с бизнесом и смежными командами. Выяснил функциональные и нефункциональные требования, которые были понятны на старте.
- Спланировал базовую архитектуру асинхронного приложения. Нагрузка в RPS небольшая, но сбор данных из сторонних API может занимать много времени.
- Разработал техзадание на инфраструктуру. Проуправлял задачами по её подготовке.
- Спланировал пайплайн CI, написал и протестировал в
GitLab, проуправлял задачами по его настройке:Docker,mypy,flake8(WPS),pytest,SonarQube. - Самостоятельно разработал асинхронное приложение. Подключил внешние и внутренние источники данных типа
АБС,SEONиCRIF. Покрыл критические участки кода юнит-тестами (pytestи плагины к нему, 100+ тестов). - Выполнил онбординг Python Backend Developer, подключил к работе по проекту, лидировал его работу, включая код-ревью. Формализовал правила командной разработки.
- Выстроил работу с QA-инженерами через проактивное общение, тест-планы и Docs-as-Code.
После создания риск-модуля решал задачи по разработке бизнес-фичей:
- изучал задачи, искал оптимальные способы решения, общался с заказчиком и внешними партнерами;
- декомпозицировал по этапам и оценивал сроки;
- разрабатывал код, включая модульные и интеграционные тесты;
- документировал;
- передавал на тестирование фичи и поддерживал процессы QA;
- выпускал в продуктивную среду, включая подготовку окружения и общение с DevOps-инженерами;
- мониторил работу приложения после релиза в
ELK,APM,Grafana,Sentry; - фиксировал выявленные баги, участвовал в расследовании инцидентов.
5. CAR.RU, контентный портал и классифайд автообъявлений¶
Декабрь 2018 — Май 2021 (2 года 6 месяцев).
Software Engineer (Python, back end)
Дополнительная информация
На момент моей работы, CAR.RU входил в ТОП-5 своей категории по данным Яндекс.Радар.
Я решал задачи в следующих областях: управление, редакция, дистрибуция, монетизация.
От меня требовалось: думать и искать точки роста доходности портала, помогать Product Owner принимать решения на основе данных, тестировать гипотезы, запускать успешные в работу. И все это в условиях ограниченных ресурсов и времени.
Каждый день и помногу писал на Python 3. Разрабатывал приложения в области AdOps и реализовывал прикладные
Machine Learning проекты: от выдвижения гипотезы до вывода ML-модели в продуктивную среду с последующими A/B-тестами и
поддержкой.
Достижения:
🥇 Главное достижение
Самостоятельно придумал и разработал на Python систему для максимизации выручки от programmatic-каналов
монетизации.
Система состояла из двух подсистем:
- Конфигуратор. Особым образом автоматизированно конфигурировал объекты в
ADFOXиGoogle AdManagerс использованием их API. Ручное выполнение этой работы заняло бы 9 человекомесяцев и не могло гарантировать отсутствие ошибок. - Максимизатор рекламной выручки. Автоматически по расписанию запрашивал в API ротаторов рекламы
ADFOXиGoogle AdManagerстатистику каждого рекламного места и изменял некоторые параметры объектов с целью максимизации рекламной выручки.
💸 Рост RPM составил +25,2%. Т.е. рекламная выручка programmatic рекламных мест выросла на четверть!
Результат был подтвержден A/B-тестом.
🥇 Продукт дал компании значимое труднокопируемое конкуретное преимущество.
- Придумал и разработал на
Pythonплатформу для планирования, проведения и оценки результатов A/B-тестов. Использовал:Google Sheets(pygsheets) для параметризации тестов и оценки результатов;T-test,Mann-Whitney,Wilcoxon,Shapiro-Wilk,Kolmogorov-Smirnov,Levene.
- Спроектировал и внедрил систему CI/CD на основе
Jenkins,Git,LinuxиDocker. Срок доставки кода в PROD-среду был сокращен до минут. Ошибки минимизированы благодаря тестированию с использованиемpytest. - Разработал на
Pythonавтоматические отчёты по монетизации: по монетизаторам, по рекламным блокам. Это позволило снизить рекламную нагрузку на пользователя на 20% за счёт увеличения экспозиции наиболее эффективных блоков и снятия неэффективных. - Спроектировал продуктовые метрики и настроил веб-аналитику. Разработал на
Pythonэкспортеры данных из всех партнёрских API. Создал единый дашборд проекта в Google Sheets, автоматически агрегирующий все ключевые метрики. Это позволяет оценивать эффект от изменений продукта.
- Лидировал изменения, снизившие на 90% пустые вызовы рекламного кода. Это улучшило CTR площадки, положительно повлияло на bid-correction, подняло средний CPM.
- Увеличил доход от размещения онлайн рекламы на 100% за счёт анализа, планирования инвентаря и настройки динамической монетизации в ротаторе ADFOX.
- Нашёл и подключил 3-х новых партнёров по монетизации: RTB, video, спецформаты. Это увеличило доход на 7%.
- С помощью A/B-тестов определил наиболее доходные форматы и дизайны RTB-блоков. Это увеличило доход на 1,5%
- Инициировал и руководил созданием системы сбора сырых данных по каналам дистрибуции контента. Проанализировал данные, нашел точки потерь и роста. Внедрил изменения в редакции и дистрибуции. Это дало рост визитов до 25% на канал.
- Нашёл и подключил 4 новых канала дистрибуции контента. Это увеличило доход на 5%.
- Лидировал изменения, увеличившие скорость взаимодействия с сайтом в среднем на 50 пп. В результате: глубина просмотра +22%, отказы -31%, время на сайте +4,7%. Выручка от рекламы выросла пропорционально.
- Лидировал изменения вёрстки, давшие рост глубины просмотра на десктопе на 28%.
- Проанализировал конкурентов, отраслевые практики и поведение пользователей. Разработал рекомендации по написанию статей. В результате глубина просмотра увеличилась на 13%, время на сайте выросло на 39%.
- Проанализировал SEO и разработал план улучшений. В результате 80% новыхстатей индексируются поисковыми машинами за 1 день.
- Минимизировал вероятность возникновения некоторых рисков за счёт анализа информации. Я умею смотреть на вещи, как собственник: юридические, налоговые, финансовые вопросы.
- Повысил сфокусированность и производительность команды, организовав работу с помощью:
Zoom,Miro,Jira Software,Confluence,TrelloиSlack.
🛠️ Мой технологический стек¶
Software Engineering¶
- Python 3:
Standard Library,asyncio,concurrent.futures,JSON,XML,REST API, regular expressions, OOP, SOLID Principles, Design Patterns. - Git:
Git,Git LFS,Git Submodules,git subtree,commitizen(Conventional Commits). - Type annotations & checking:
typing,collections.abc,typeguard,pydantic. - Static Code Analysis:
mypy,wemake-python-styleguide(flake8),SonarLint+SonarQube,isort,bandit,nitpick(3),pre-commit. - Frameworks:
FastAPI+Starlette+Uvicorn,Flask+RestX. - Testing:
pytest,coverage,tox,hypothesis,schemathesis,Postman,locust(2). - Documenting:
Material for MkDocs,mkdocstrings. - DB:
PostgreSQL,PGAdmin4,psycopg2,asyncpg,SQLAlchemy,Databases,alembic. - Dependency management:
poetry,venv,pip,pip-tools,Conda/Anaconda. - Packaging:
poetry(1),setuptools,wheel,build,twine. - HTTP clients:
aiohttp,requests,httpx. - Message Brokers:
Apache Kafka,IBM MQ(AMQP).
- Во всех новых проектах я использую только
poetry. - Использую для нагрузочного тестирования.
- Использую для: сетапа новых репо, синхронизации и enforcing настроек множества проектов.
DevOps (DORA)¶
Docker,docker-compose,OpenShift/Kubernetes (K8S),Helm,Ansible(1),ArgoCD.- CI/CD/CT:
GitHub flow(3),GitLab CI,Jenkins,Bitbucket,bash(2). - Logging:
logging,ELK. - Monitoring:
Prometheus,Grafana,Alertmanager,Sentry,APM,Jaeger. - OS:
Linux(Debian,Ubuntu),Windows Server,Windows 10 Professional+WSL.
- Включая разработку своих
Ansible-ролей. - Разработал библиотеку
bash-скриптов, которой пользуюсь я и коллеги DevOps-инженеры. - Хотел бы поработать в проекте, где применяется Trunk-based Development (TBD).
MLOps (CRISP-ML(Q))¶
Apache Airflow,Apache Spark,MLFlow,DVC,Seldon Core.- Data Distribution Shifts (1) : Covariate shift, Label shift, Concept drift. Фреймворки:
Alibi Detect,whylogs. - Data markup:
Yandex Toloka for customers. - A/B testing:
T-test,Mann-Whitney,Wilcoxon,Shapiro-Wilk,Kolmogorov-Smirnov,Levene.
- Ещё известно как "дрифт ML-моделей / дрифт данных".
ML Engineering¶
- ML:
pandas,numpy,scipy,scikit-learn,matplotlib,LightGBM,prophet,XGBoost,CatBoost,Random Forest,K-means,Hierarchical clustering,logistic regression,linear regression,supervised learning,unsupervised learning. - Applied analysis:
Excel(linear programming,RFM,ABC,XYZ analysis),Google Sheets.
Publisher Related¶
- Programmatic-monetization:
ADFOX API,API of the Affiliate Interface(Yandex Advertising Network),Google AdSense API,Google AdManager API. - Content distribution:
Turbo-pages,AMP,Google News,Yandex Zen,Google Search Console,Yandex Webmaster,Bing Webmaster. - Web analytics:
Google Analytics API,Yandex Metrica API,Google Tag Manager.
⏱️Часовой пояс и рабочее время¶
Часовой пояс: 🇷🇺 Россия, Тюмень, МСК +02:00.
Рабочее время: МСК 07:00 — 16:00. В этот период я доступен для синхронных коммуникаций.
Как показывает практика, с таким режимом работы не возникает сложностей при работе с коллегами из Москвы. Наоборот, получается даже более эффективно. В первой половине дня я сконцентрирован на технических задачах. Звонки проводятся в период с 14:00 до 16:00 МСК (16:00 - 18:00 ТМН). К этому моменту я уже отработал 6 рабочих часов и выдал максимум результата.
Режим ненормированного рабочего дня → возможно, но будет дороже 💸
Частые овертаймы приводят к быстрому выгоранию 🔥 и последующему увольнению из компании. Это не то, чего я хочу.
Поэтому, если в вашем трудовом договоре указан ненормированный рабочий день, то это обойдется вам дороже.
При этом, если иногда нужно что-то срочно починить в проде, то это с этим нет никаких проблем.
Что меня мотивирует и демотивирует¶
🛑 Стоп-факторы¶
Даже не предлагайте мне
Я не работаю как ИП, самозанятый или по договору ГПХ. Работаю только по трудовому договору в соответствии с ТК РФ.
Причина - у меня ипотека и двое детей.
Возможно, но будет дороже 💸
Недавнее массовое увольнение инженеров.
Это само по себе вызывает вопросы. Помимо этого, никто не проведёт онбординг. Придётся приложить массу усилий, чтобы разобраться в заявках, инфраструктуре, подготовить рабочую среду и т.п. И только потом ты сможешь выдавать результат.
На это может уйти полгода жизни. Мне есть, чем его занять.
Это не моя компания, а я не её кандидат, если:
-
Нет готовности к полной удалёнке с территории РФ.
Проверьте ваш трудовой договор
Трудовой договор должен предусматривать выполнение работником трудовой функции дистанционно на постоянной основе (в течение срока действия трудового договора).
Не временную. Не периодическую. И точно не рабочее место в офисе.
-
Слабый непосредственный руководитель, не разбирающийся в производственных процессах: "Я человек простой, назови мне срок".
Цитата из ревью 'Senior Software Vlogger' на книгу 'Quality Software Management' от Gerald M. Weinberg:
Что я могу сказать закончив читать книгу 1997 года? Как сам Джеральд пишет в книге: плохой менеджмент порождает 2/3 проблем в разработке софта. Само кодописание приносит настолько меньше проблем, что этим числом можно пренебречь.
Тем не менее, как продолжает Джеральд, чаще фокусируются на улучшении не менеджмента, а процесса написания кода.
Кто бы мог догадаться, что самые устаревшие пара глав в книге - как раз про улучшение кода. Мы все уже пишем тесты, ревьювим дизайн архитектуры и код. Используем системы контроля версий и хаос тестирование.
Но мы точно так же про@#$ваем планирование проектов, работу с требованиями к системе и процессы в целом.
-
Перекосы в структуре, когда слишком много руководителей.
Мой личный рекорд — совещание по запуску сервиса, где я один отвечал на вопросы 6 (шести!) руководителей.Рекорд побит! 14 участников, из них 2 инженера:-) - Регулярные переработки. Предложения поработать в отпуске.
- Тайм-трекинг. Внедрение подобных инициатив по «повышению эффективности» — верный признак того, что в компании всё плохо. Ей уже некогда заниматься новыми проектами.
- Разные должности или уровни компенсации на испытательном сроке и после него.
- Размытая зона ответственности. Нужно понимать конкретно. Увольняют именно за то, что ты с этим не справился.
- KPI без инструментов и условий для их достижения.
⛔ Какие компании не подходят¶
- ИТ-интеграторы, веб-студии, аутстафф, аутсорсинг️, продакшн или перфоманс агентства, где производственные процессы выстроены по принципу галер 🚣.
- 👶 Недавно созданные компании с микроскопическим уставным капиталом и средней численностью персонала.
- Я не работаю с теми, кто приносит больше вреда, чем пользы: форекс, МЛМ, бинарные опционы, крипта, азартные игры и т.д. Для меня важно, чтобы работа была значимой, полезной и ею можно было гордиться.
- Я не буду работать в командах с плохой корпоративной культурой. Мне нравятся меритократические системы управления.
- С отрицательной репутацией.
- Я не работаю в компаниях с «серыми» зарплатами.
👍 Какие компании привлекательны¶
- 💸 Компании, где IT == бизнес.
- 🚀 Растущие продуктовые компании.
💎 Какие проекты привлекательны¶
Идеальный проект — прибыльный, который стартовал из-за роста бизнеса. У него:
- Сильная управленческая команда, имеющая успешный опыт в прошлом.
- Сильная команда инженеров — хороших людей. Пусть это будут прямые, даже несколько грубые люди, но зато с сильной этикой.
- Обоснованно используется современный технологический стек.
- Отлаженные процессы разработки и доставки в продуктивную среду.
Возможно, но будет дороже 💸
Проекты с нуля. С только что созданными отделами без инженерной команды, данных, процессов, культуры.
👌 Будет плюсом¶
- Безопасники не «терроризируют» разработку. Взаимодействие происходит конструктивно.
- Выделяются ресурсы и время для R&D: изучение лучших практик, архитектур, технологий.
- Если обязательна работа на корпоративном ноутбуке, то 14" ноутбук на Linux/MacOS (не Windows!) и док-станция к нему.
- ДМС с первого месяца с нормальными клиниками.
- Есть бюджет на обучение. Есть возможность оплачивать курсы на Udemy и Coursera.
👨🎓 Я постоянно учусь¶
Для достижения своей цели я хочу углубить свои знания и навыки в следующих областях:
- дизайна масштабируемых и надежных ML систем;
- разработки программного обеспечения на Python;
- DevOps;
- MLOps и Data Engineering;
- SRE.
1. Systems Design¶
- ✅

Building Microservices, 2nd Edition - Sam Newman.→ см. мой обзор на книгу. - ✅
Designing Data Intensive Applications — Martin Kleppmann — 2017. - ✅
Курс «System Design» от karpov.courses. - Kubernetes Patterns, 2nd Edition — 2023. Объём 478 страниц.
- Software Requirements, 3rd Edition, 2013.
- Software Architecture for Busy Developers, 2021.
- Software Architecture: The Hard Parts, 2021. Написана консультантами из Thoughtworks. Объём 416 страниц.
- The System Design Primer.
2. ML Systems Design¶
- Курс Stanford CS329S ML Systems Design, Winter 2022.
- Designing Machine Learning Systems (Chip Huyen 2022).
- Machine Learning Interviews Book (Chip Huyen).
- applied-ml.
- Machine Learning Design Patterns — 2020.
3. Python¶
- Fluent Python, 2nd Edition — 2022.
- Python in a Nutshell, 4th Edition — 2023.
- Python Concurrency with
asyncio— 2022.
4. DevOps¶
- Kubernetes:
- ✅
Изучение материалов в рамках программы Certified Kubernetes Application Developer(CKAD). - При необходимости углубиться в каком-то вопросе, я изучаю материалы из программы Certified Kubernetes Administrator (CKA).
- ✅
- Terraform, Terragrunt.
- CompTIA Linux+ Certification All-in-One Exam Guide — 2023.
5. MLOps¶
Communities¶
- MLOps.community.
- MLечный путь — сообщество ML и MLOps инженеров.
Courses¶
Books¶
- Effective Machine Learning Teams — 2024.
- Implementing MLOps in the Enterprise — 2024.
- Architecting Data and Machine Learning Platforms — 2023.
- Practical MLOps — 2021.
- Introducing MLOps — 2020.
Data Engineering¶
- Курс «Инженер данных» от karpov.courses.
- Курс «Экосистема Spark, Hadoop, Hive» — Егор Матешук.
Apache Spark¶
- ✅
Apache Spark и Scala для дата-инжиниринга, курс от Newprolab. - High Performance Spark, 2nd Edition — 2024.
- Scaling Machine Learning with Spark — 2023.
- Learning Spark, 2nd Edition — 2020.
Apache Kafka¶
- Kafka: The Definitive Guide, 2nd Edition — 2021.
- Scott D., Gamov V., Klein D. — Kafka in Action — 2022.
Feature Stores¶
GPU¶
- ✅
NVIDIA Cloud Native Technologies. - NVIDIA Triton Inference Server.
- NVIDIA-Certified Associate (NCA-AIDC): AI in the Data Center.
Deep Learning¶
- MIT 6.S191 Introduction to Deep Learning — 2024.
- MIT 6.5930/1 Hardware Architecture for Deep Learning — 2024.
6. SRE¶
- ✅
Курс МТС.Тета — SRE: Стратегии и Методы. - Site Reliability Engineering.
- The Site Reliability Workbook.
- Building Secure & Reliable Systems.
- Reliable Machine Learning — 2022.
Организация высокоэффективных команд разработки¶
- ✅
Team Topologies - Matthew Skelton, Manuel Pais. - ✅
Accelerate - Building and Scaling High Performing Technology Organisations - Nicole Fergrson.
Фреймворки для проектирования систем¶
Изучение фреймворков и инструментов для анализа требований и проектирования систем. Адаптация для выработки собственного подхода и шаблонов документов.
Например:
- C4 model.
- ✅ Старый добрый ГОСТ 34 + смежные ГОСТ и РД. Без фанатизма.
- Шаблоны схем. Наборы stencils.
- Шаблоны презентаций.
- Шаблоны документов.
💬 Свяжитесь со мной¶
Пожалуйста, не стесняйтесь писать мне: