NVIDIA Cloud Native Technologies¶

Ресурсы и документация¶
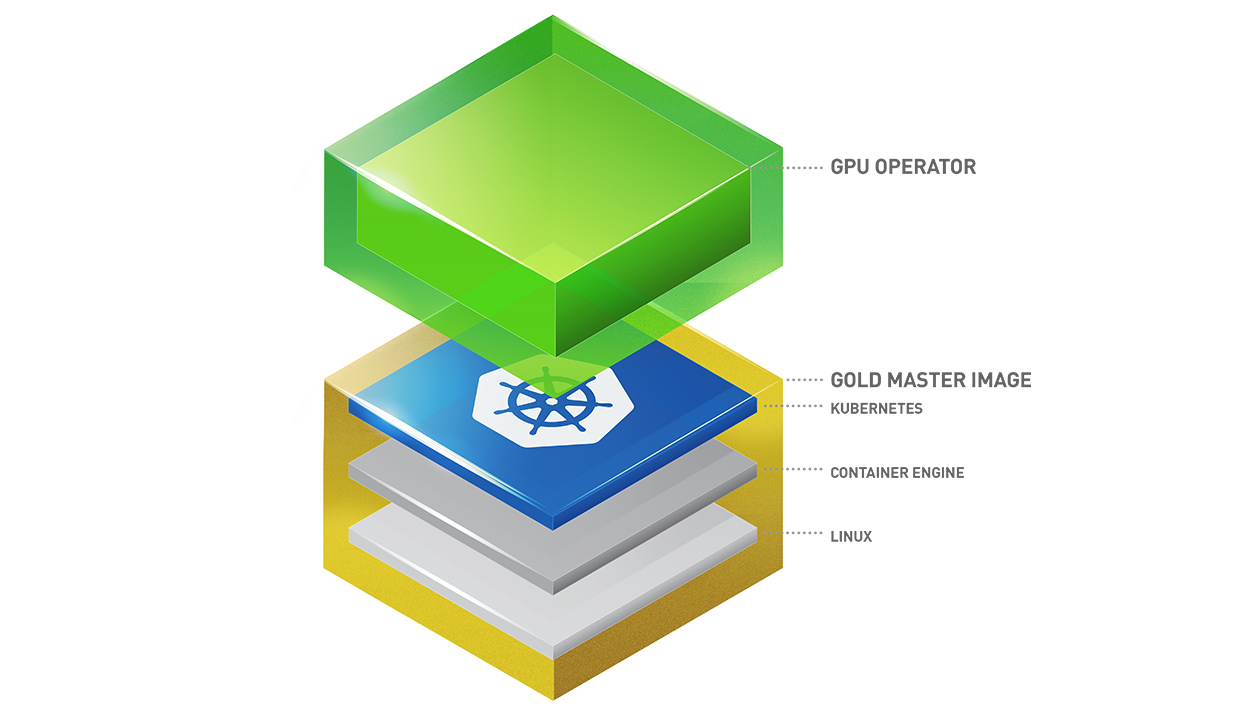
NVIDIA GPU Operator¶
- Документация NVIDIA GPU Operator.
- Документация NVIDIA GPU Operator on Red Hat OpenShift Container Platform.
- Репозиторий GitHub NVIDIA/gpu-operator.
The GPU Operator allows administrators of Kubernetes clusters to manage GPU nodes just like CPU nodes in the cluster. Instead of provisioning a special OS image for GPU nodes, administrators can rely on a standard OS image for both CPU and GPU nodes and then rely on the GPU Operator to provision the required software components for GPUs.
Note that the GPU Operator is specifically useful for scenarios where the Kubernetes cluster needs to scale quickly - for example provisioning additional GPU nodes on the cloud or on-prem and managing the lifecycle of the underlying software components. Since the GPU Operator runs everything as containers including NVIDIA drivers, the administrators can easily swap various components - simply by starting or stopping containers.
NVIDIA Data Center GPU Manager (DCGM)¶
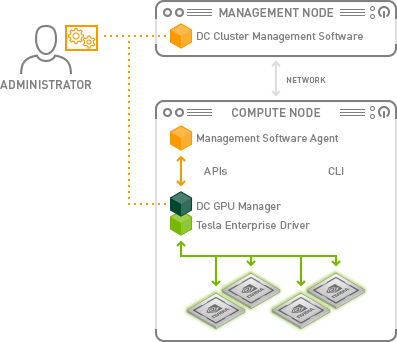
- Документация NVIDIA DCGM.
- Репозиторий GitHub NVIDIA/DCGM.
NVIDIA DCGM Exporter¶
- Документация NVIDIA DCGM Exporter.
- Репозиторий GitHub NVIDIA/DCGM-Exporter.
- Таблица с описанием метрик по умолчанию на дашборде NVIDIA DCGM Exporter Graphs.
- Grafana NVIDIA DCGM Exporter Dashboard.
The GPU Operator exposes GPU telemetry for Prometheus by using the NVIDIA DCGM Exporter.
По умолчанию экспортируется ограниченный набор метрик: /etc/default-counters.csv.
Но его можно изменить, см. Changing Metrics.
Полный список счетчиков, которые могут быть собраны, можно найти в справочном
руководстве по DCGM API: Field Identifiers.
NVIDIA Container Toolkit¶
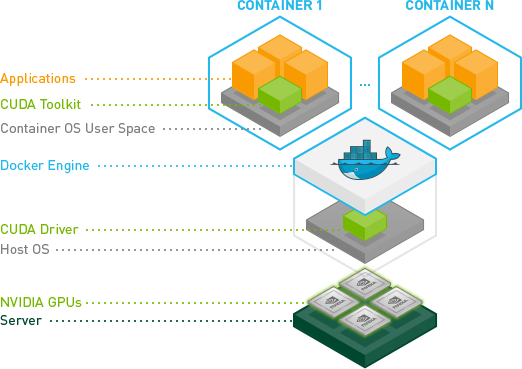
- Документация NVIDIA Container Toolkit.
- Репозиторий GitHub NVIDIA/nvidia-container-toolkit.
The NVIDIA Container Toolkit allows users to build and run GPU accelerated containers. The toolkit includes a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs.
MIG Support in OpenShift Container Platform¶
NVIDIA Mult-Instance GPU (MIG) is useful anytime you have an application that does not require the full power of an entire GPU. The new NVIDIA Ampere architecture’s MIG feature allows you to split your hardware resources into multiple GPU instances, each exposed to the operating system as an independent CUDA-enabled GPU. The NVIDIA GPU Operator version 1.7.0 and above provides MIG feature support for the A100 and A30 Ampere cards. These GPU instances are designed to support multiple independent CUDA applications (up to 7), so they operate completely isolated from each other using dedicated hardware resources.
The compute units of the GPU, in addition to its memory, can be partitioned into multiple MIG instances. Each of these instances presents as a stand-alone GPU device from the system perspective and can be bound to any application, container, or virtual machine running on the node.
From the perspective of the software consuming the GPU each of these MIG instances looks like its own individual GPU.
Time-slicing NVIDIA GPUs in OpenShift¶
The latest generations of NVIDIA GPUs provide a mode of operation called Multi-Instance GPU (MIG). MIG allows you to partition a GPU into several smaller, predefined instances, each of which looks like a mini-GPU that provides memory and fault isolation at the hardware layer. Users can share access to a GPU by running their workloads on one of these predefined instances instead of the full GPU.
This document describes a new mechanism for enabling time-sharing of GPUs in OpenShift. It allows a cluster administrator to define a set of replicas for a GPU, each of which can be handed out independently to a pod to run workloads on.
Unlike MIG, there is no memory or fault-isolation between replicas, but for some workloads this is better than not being able to share at all. Under the hood, Compute Unified Device Architecture (CUDA) time-slicing is used to multiplex workloads from replicas of the same underlying GPU.